Hello,
I noticed that data coming from the Rich Text Editor is being rendered with raw HTML tags (e.g., <strong>, <p>, etc.) when processed by the template engine.
Could you please confirm if this is the expected behavior, or if there is a way to automatically sanitize/strip those tags during template rendering?
1 Like
Corteza uses bluemonday to make sure the contents are safe. The rich-text editor is based on HTML tags so if you don’t want them, I’d suggest you use a plain editor
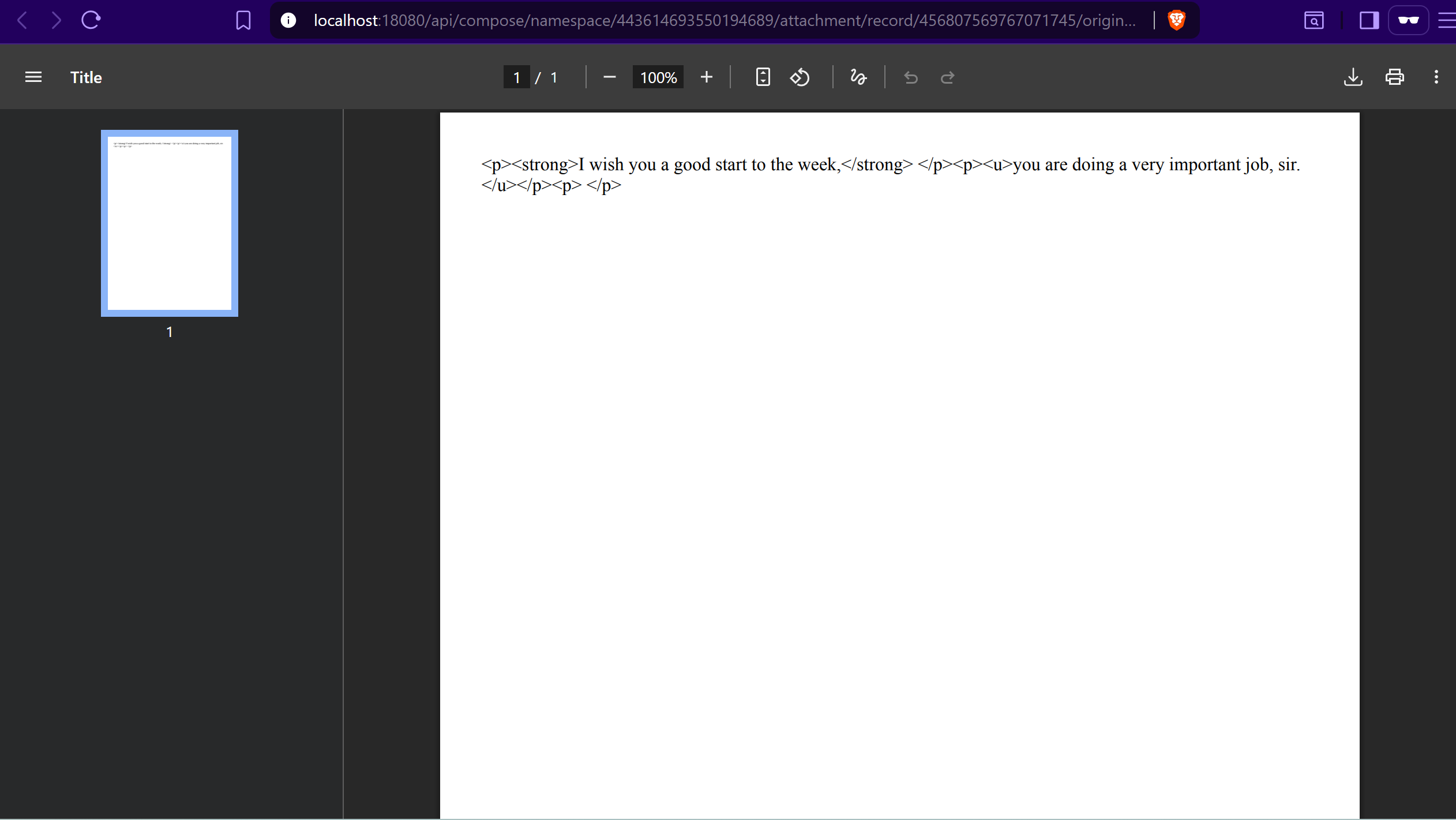
Thanks for your feedback. As you can see in the screenshot, the HTML tags appear in the final output for text edited with the rich text editor. I tried using the plain text editor, but it’s not well-suited for long texts like contracts and similar documents.
1 Like
Ah, ok I remember now (ref)… The underlying library is too strict and we’d need to add some extra bits and pieces to make this work.
What I would recommend is:
- Place most of the contents in the template itself (for your contract example, write everything in the template and leave
{{.firstName}}, {{.lastName}}, … as variables)
- Change the record so you’ll only provide the few missing pieces instead of the entire document/contract.
For now, this is what comes to mind; I can’t promise a timeline on when rich text will be better supported.
Thank you for the proposed solutions.
1 Like
Hi @tjerman, I tried the proposed solution, and it’s quite tedious. It leads to the creation of a large number of templates for each document variant. Moreover, it’s impossible to use the simple multiline editor due to the line concatenation issue, as mentioned in the post you referenced.
It would be really interesting to have the ability to configure which HTML tags to preserve, similar to the bluemonday.UGCPolicy() function.
This is just a suggestion for future versions.
Goodbye, and thanks again.
1 Like