We are two modules on with 55K records and one with 300K records. Each module have around 6-7 fields. For the one with the 300K records it is taking around 24 seconds for the page to load, we have paging enabled with only 20 records per page. Is there a setting to optimize or any recommendation for optimization of the initial data load. We are using the latest release .9.5
This is one of the ghosts from the past we need to deal with as to how the records were initially designed.
We will be improving this in future releases (potentially in 2022.9 but we might already start addressing it in 2022.3; although unlikely).
If you wish to make the loading faster you can try a few things:
Reduce the size of the dataset (reduce the number of records)
Instead of having some type/status/kind field, create different modules to hold different records.
You can use automation to automatically move records between the two.
Perhaps my answer back here Setting up filter on global variable provides describes a solution that would reduce the size and make it faster.
Use system fields for filtering/sorting
System fields are indexed so those should work somewhat faster.
If you don’t need any special sorting/filtering consider removing it and only use system stuff.
Disable go to page and record count options
In the record list config screen there are two options that allow you to hide the total records count and the list of available pages.
Corteza implemented paging cursors back in (IIRC) 2020.12.x so those pages are calculated on demand which would take some processing if you have a large dataset.
Thank you, by removing the record count and paging, the page load on 2000k+ records is now under 3 seconds.
We still need to figure out ability to filter the data on data in other modules

We don’t have a native solution to this (yet); here is an option:
Module A references module B via field fA (A -fA-> B).
You wish to filter A records based on the field fB inside module B.
You could define an automation that would copy the value of fB into the corresponding A record (let’s call the copy of the field fB'); the automation would need to keep the value synced up.
You could then define a prefilter over fB' inside A.
Not an ideal solution but it would do the trick.
We were discussing a native solution but we didn’t want to rush it as it’s not as straightforward as one would hope.
Just to add to the challenge above for us, if we have multiple users working on different data records in FA, then we need to be able to automate which data record is being worked on by a specific user, the above solution would work would mean every one working on same record. That is what we were trying to do by having another module that is keeping track of the user and the record being worked on and see if we can filter the data on that. If thier is a way in the filter to query and get a record value to set as the filter from another module that would provide a lot of capability. I think you already do some thing similar when you do a parent record, if the parent record can be queried and filter on that, some thing to consider
Not necessarily; if you configure your prefilters properly then you can have different users working on different records (we call them records instead of data records so I will use that terminology).
If you wish to have multiple users working on the same record, you can use multi-value fields to achieve that.
Appending to your example; let’s say we have a module to keep track of who is working on what records.
When you add/update/remove an entry to that bookkeeping module, you would update the corresponding records and set the fB' field I was referring to in my earlier reply.
Then, your prefilters would allow you to filter out any records the user doesn’t care about (remember – prefilters allow value interpolation, meaning that you can somewhat personalize the prefilter based on the context).
We also support contextual roles which allow you to implement some dynamics to the access control based on the context. I don’t see how those could be used here, but you might find them handy.
I have found the code in 2022.9 branch to refactor store. I still have some questions. Could you please explain more?
-
order byandfilterstill slow after using json to store compose-records-values, can we create index on json fields when creating modules? - maybe sql database not suitable for this data purpose, can some no-sql database like mongodb can solve this? will you support no-sql databse in future?
Some DB engines support indexes on JSON properties which would be a solution.
Alternatively, you’ll have the option to store those records in a dedicated table.
At some point, Corteza will provide an interface to configure DB indexes but potentially not in the initial 2022.9 release.
You’ll need to do more manual DB maintenance until it does.
Most likely, yes, but don’t hold me on that.
The added capability for modules to use dedicated tables should solve most of our data-related problems.
Really Thanks ![]()
I still have two concerns,
- I will have a option from web to store module into a table, which contains only this module’s data?
- This table still store data as
jsonor individual fields?
You’ll have a bunch of options allowing you to specify into what table (so yes, you can do one module per table) and what column the specific module and its fields should get stored.
The initial version will support storing module fields in dedicated columns and in a simple JSON object ({ key: [value] } – the one used for the pre-defined records table).
Later versions will most likely allow you to define an arbitrary JSON object for more flexibility.
1 Like
Is there any update about this answer? Perhaps there’s now a solution that enables adding a filter in the ‘Record List’ to access fields from another module?
Or maybe I can add a ‘Record field’ to my module that will copy value from another module?
The have been a lot of improvements over the last two years (because the original post in from January 2022).
Referring to the original question: speed has improved a lot in the 2023.9 release. And further down the thread the discussion shifted to fields from other modules: now you can natively show data of related records in a record page, using the “Reference record field” selector.
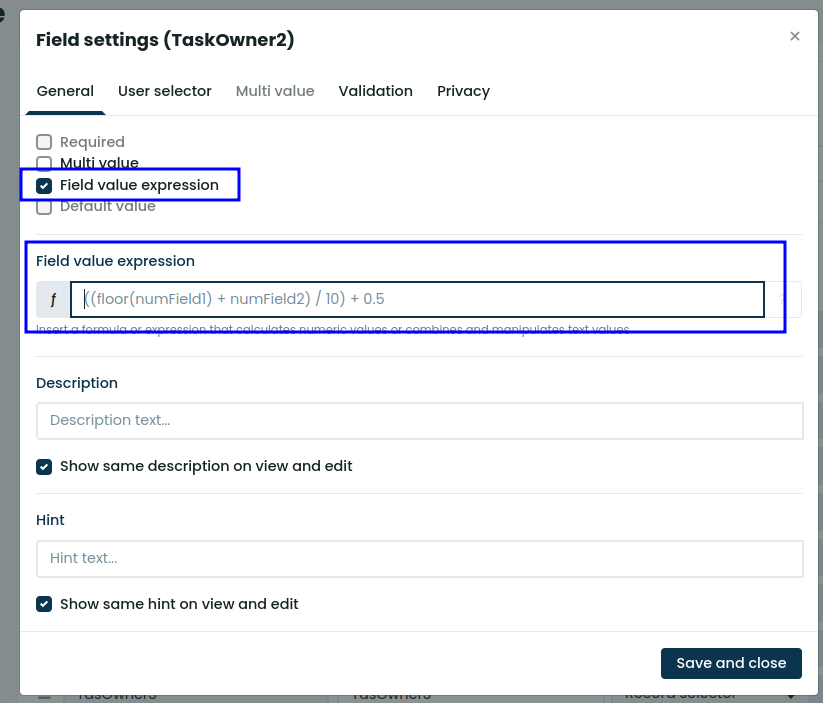
However, cross module filters on record lists don’t exist natively. If this is what you require the easiest is to copy the required fields over to the module you want your filter on.
For example, let’s say you have these module:
Employee
- Name (string)
- Email (email)
- Country (string)
Task
- Description (string)
- DueDate (datetime)
- EmployeeId (record selector linking to “Employee”, showing the name)
You can make a tasks list which shows the employee’s name and task details. But, now you want to filter the list on country, which comes from the selected employee.
In that case you need to add the country field to the “Task” module:
Task
- Description (string)
- DueDate (datetime)
- EmployeeId (record selector linking to “Employee”, showing the name)
- Country (record selector linking to “Employee”, showing the country)
And in this field, you have an expression that links to the EmployeeId field in the Task module.
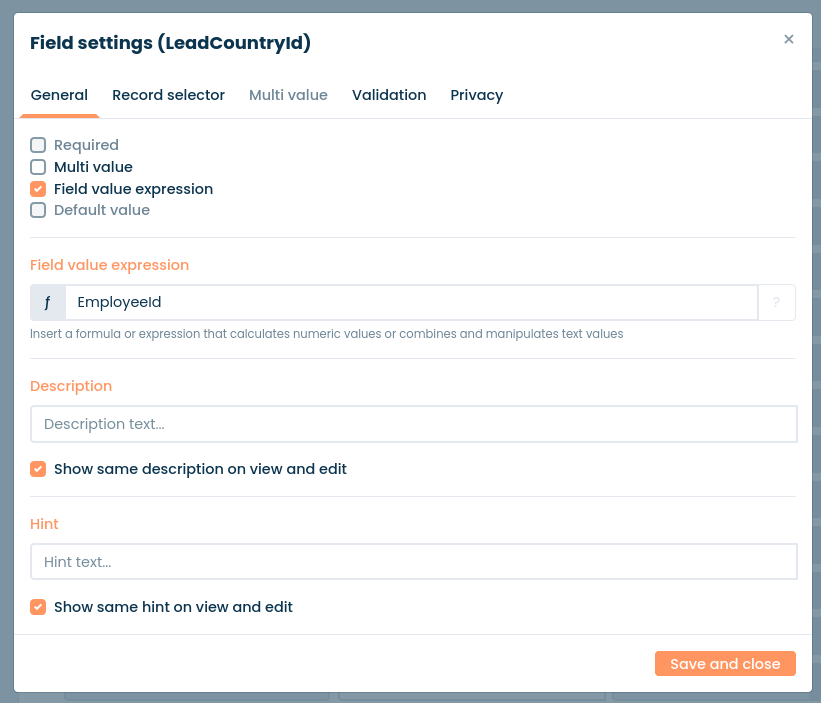
So, now, whenever a Task record is created or updated, this country reference ID is also updated.

The only thing that you will need to decide on is what has to happen when the country of the lead changes. In the solution above the country in the Task will change as well (because it’s just a reference to the Employee’s module that’s stored), but sometimes you don’t want that to happen. If you don’t want to retroactively have all values updated, you’ll need the “Country” field in the Task module to be of a string type, and fill it via a workflow after a note is created or updated (and not when an employee is modified).
Hope this helps.
3 Likes
Thank you so much for the quick response. It was very helpful!